General Policy Evaluation and Improvement by Learning to Identify Few But Crucial States
Francesco Faccio, Vincent Herrmann, Aditya Ramesh, Louis Kirsch, Jürgen Schmidhuber
Abstract
Learning to evaluate and improve policies is a core problem of Reinforcement Learning (RL).
Traditional RL algorithms learn a value function defined for a single policy.
A recently explored competitive alternative is to learn a single value function for many policies.
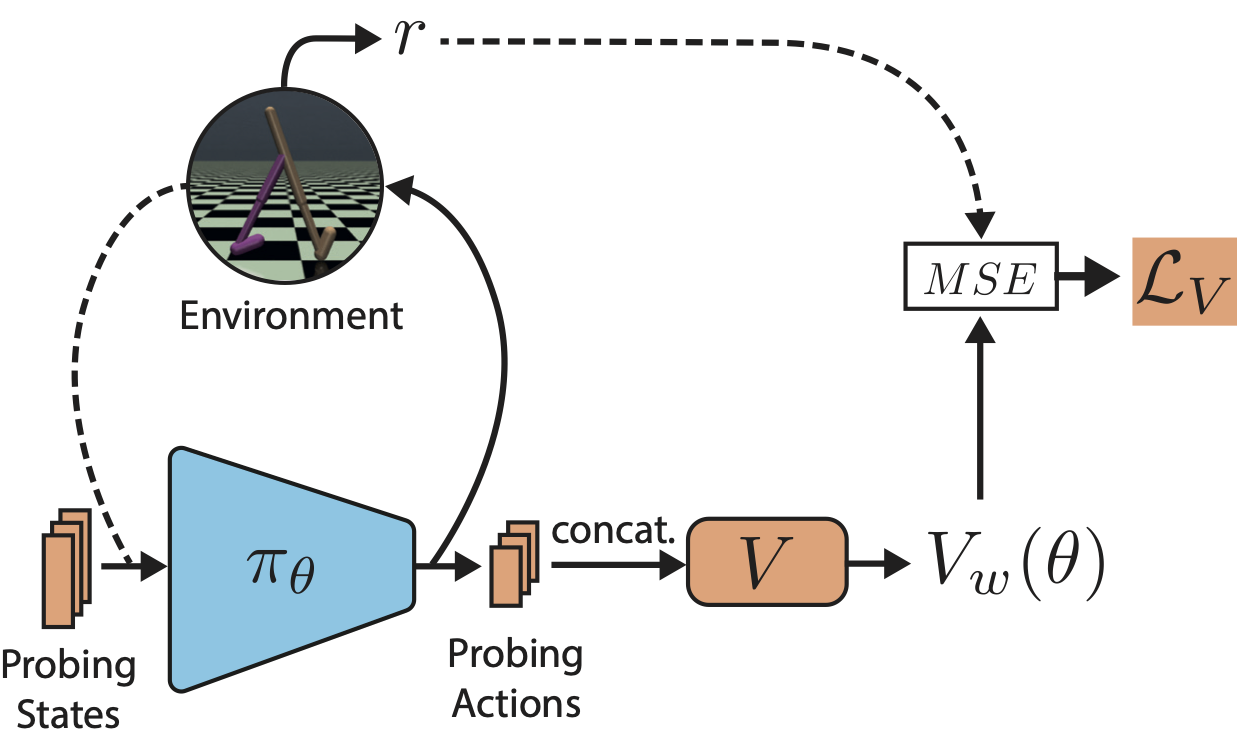
Here we combine the actor-critic architecture of Parameter-Based Value Functions and the policy embedding of Policy Evaluation Networks to learn a single value function for evaluating (and thus helping to improve) any policy represented by a deep neural network (NN).
The method yields competitive experimental results.
In continuous control problems with infinitely many states, our value function minimizes its prediction error by simultaneously learning a small set of `probing states’ and a mapping from actions produced in probing states to the policy’s return.
The method extracts crucial abstract knowledge about the environment in form of very few states sufficient to fully specify the behavior of many policies.
A policy improves solely by changing actions in probing states, following the gradient of the value function’s predictions.
Surprisingly, it is possible to clone the behavior of a near-optimal policy in Swimmer-v3 and Hopper-v3 environments only by knowing how to act in 3 and 5 such learned states, respectively.
Remarkably, our value function trained to evaluate NN policies is also invariant to changes of the policy architecture: we show that it allows for zero-shot learning of linear policies competitive with the best policy seen during training.
Paper
Code
Probing States Visualization
Hopper
Probing States of Untrained PSSVF





Probing States of Trained PSSVF





Swimmer
Probing States of Untrained PSSVF





Probing States of Trained PSSVF





HalfCheetah
Probing States of Untrained PSSVF




















Probing States of Trained PSSVF




















Ant
Probing States of Untrained PSSVF








































Probing States of Trained PSSVF








































Walker2d
Probing States of Untrained PSSVF


















































Probing States of Trained PSSVF

















































